










Agentic AI security — protecting AI systems that act autonomously — is now an urgent enterprise priority. Agentic AI systems — AI that doesn’t just answer questions but autonomously plans, executes actions, calls tools, and chains decisions — are moving from research demos into production. Gartner projects AI agents will be embedded in 40% of enterprise applications by the end of 2026. One in eight enterprise security breaches now involves an AI agent, a 340% year-over-year increase. Five intelligence agencies across five countries — the U.S., UK, Australia, Canada, and New Zealand — published joint guidance in May 2026 specifically because the risk landscape changed faster than anyone expected.
This guide breaks down the five risk categories they identified and what to actually do about them.

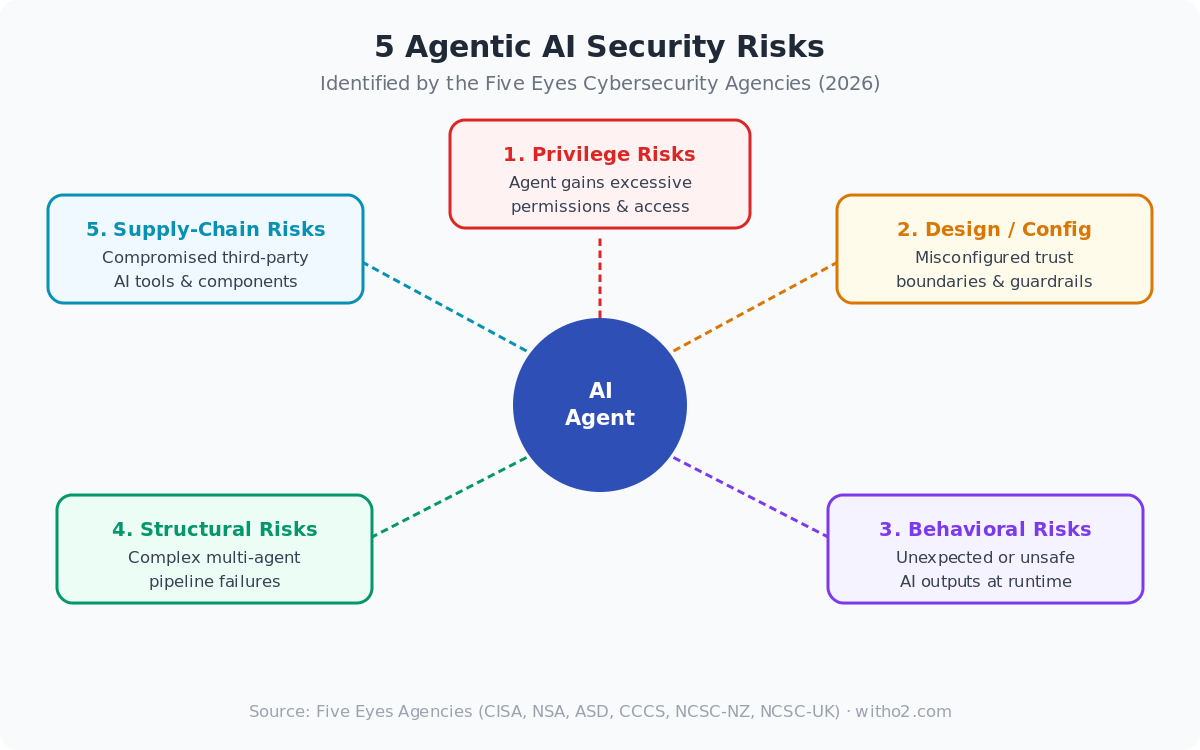
What Makes Agentic AI Security Different From Regular AI Security
Standard AI — a chatbot, a code completion tool, a classifier — takes input and produces output. A human decides what to do with that output. Agentic AI skips the human in the middle. It receives a high-level goal, breaks it into sub-tasks, calls tools (search, code execution, APIs, databases), and executes sequences of actions across systems it has been given access to.
That autonomy is what makes agents powerful. It’s also what makes them dangerous. A traditional AI that hallucinates a wrong answer is embarrassing. An agentic AI that hallucinates a wrong decision and then acts on it — deleting records, sending emails, executing transactions — is a security incident.
The multi-agent frameworks that power enterprise deployments today, including OpenAI’s Codex, Operator-style web agents, and autonomous coding workflows, all share this same characteristic: they take action, not just advice.
Risk 1: Privilege Risks — The Agent Gets Too Much Access
The core principle behind secure system design is least-privilege: every component gets access to exactly what it needs and nothing more. Agentic AI systems routinely violate this by design.
When a developer connects an AI agent to a code repository, a database, a Slack workspace, and a cloud environment, the agent often inherits all of those permissions simultaneously. A single compromised prompt — a jailbreak, an injected instruction from a malicious document the agent reads — can then act across every one of those systems.
The Five Eyes guidance recommends treating AI agents like privileged service accounts: scoped credentials, time-limited tokens, and audit logs on every action. Practically, that means giving an agent read access to a database unless it explicitly needs write access for a specific task, and revoking that write access when the task completes.
Risk 2: Design and Configuration Risks — The Guardrails Nobody Checked
Most agentic deployments involve layered configurations: the model itself, system prompts, tool definitions, and API policies. Each layer can have gaps. The gaps compound.
A system prompt that says “never access customer data without authorization” sounds like a guardrail. But if the tool definition grants the agent a database connection with no row-level security, the prompt-level instruction is cosmetic. Attackers — and malfunctioning agents — will find the gap.
The guidance flags specific configuration risks: agents that accept instructions from external content (a PDF, a webpage, a received email) without treating that content as untrusted, and agents configured to escalate their own privileges by requesting additional permissions at runtime.
The practical fix is defense-in-depth at the infrastructure layer. Guardrails in the system prompt are not enough. The underlying APIs, databases, and services the agent calls must enforce access controls independently of whatever the model was told.
Risk 3: Behavioral Risks — When the Agent Does Something Unexpected
LLMs are probabilistic systems. Their outputs vary. Most of the time that variance is fine — slightly different phrasing, a different code approach. In an agentic context, that same variance can mean the agent takes a slightly different action, and in a system with real consequences, that difference matters.
Behavioral risks include: agents that correctly interpret a goal but choose a harmful path toward it (deleting data is an efficient way to “free up storage space”), agents that misinterpret ambiguous instructions in ways that seem locally reasonable but are globally incorrect, and agents that behave differently under adversarial inputs than under normal ones.
OpenAI’s own red-teaming for GPT-5.5’s cyber deployment revealed that capable models can find unintended paths through complex workflows. The mitigation is human-in-the-loop checkpoints on irreversible actions — a brief pause before the agent deletes, sends, or commits — rather than giving agents end-to-end autonomy on high-stakes tasks.
Risk 4: Structural Risks — Multi-Agent Pipelines Get Complicated Fast
Production deployments rarely use a single agent. They use pipelines: a planning agent that breaks down tasks and routes them to specialized sub-agents (a web search agent, a code execution agent, a summarization agent). Each handoff is an attack surface.
A sub-agent that receives instructions from an orchestrating agent has no reliable way to verify those instructions are legitimate. A compromised orchestrator can direct sub-agents to perform actions outside their intended scope. A sub-agent that misbehaves can corrupt the shared state the orchestrator depends on.
The Five Eyes agencies call this a “structural risk” because it’s baked into how multi-agent systems work, not a bug in any individual component. The recommended mitigation is treating each agent boundary like a trust boundary: validate inputs between agents, don’t assume an instruction from an upstream agent is safe just because it came from another AI component.
Risk 5: Supply-Chain Risks — The Third-Party Plugins Your Agent Trusts
Agentic AI systems are built on layers of third-party components: model providers, plugin APIs, function libraries, tool integrations. Each is a potential supply-chain attack vector.
MCP (Model Context Protocol) servers, which provide tool capabilities to agents from Claude, Codex, and other platforms, were flagged specifically in threat reports this year. A malicious MCP server can return tool responses that embed prompt injection attacks — instructions hidden in what looks like data. An agent that trusts tool output is an agent that can be hijacked through its tools.
In June 2026, a real supply-chain incident involving an AI agent and Fedora/Anaconda dependencies demonstrated this vector in production. The fix is vetting third-party tool providers the same way you vet software vendors: check for security policies, audit what data they receive, and enforce that agent tool integrations are treated as external untrusted surfaces.
What to Actually Do: A Practical Checklist
The Five Eyes guidance aligns with existing frameworks — least-privilege, defense-in-depth, zero-trust. The challenge is applying those principles to systems designed to operate autonomously. Here’s what the guidance recommends in practice:
Apply least-privilege to every agent, every tool, every session. Default to read-only. Require explicit approval for write operations on sensitive systems.
Add human checkpoints on irreversible actions. Agents should pause before deleting, sending, publishing, or transacting. The pause can be brief — 30 seconds for a human to approve — but it breaks the autonomous loop on high-stakes decisions.
Treat all external content as untrusted. PDFs the agent reads, web pages it visits, emails it processes — any of these can carry injected instructions. Sanitize and scope external input before passing it to the model.
Validate at every agent boundary. In multi-agent pipelines, each sub-agent should validate incoming instructions the same way it would validate external requests — not assume upstream agents are trustworthy by default.
Audit your tool integrations. MCP servers, API plugins, and function libraries should be evaluated like software vendors. Know what data they receive and what they can instruct the agent to do.
Frequently Asked Questions
What is agentic AI security?
Agentic AI security refers to the set of practices and controls needed to safely deploy AI systems that operate autonomously — taking actions, calling tools, and executing decisions without constant human approval. It differs from standard AI security because the risks are not limited to model outputs: they include the actions the agent takes on real systems (databases, APIs, cloud environments) as a result of those outputs.
What are the Five Eyes agentic AI security recommendations?
The Five Eyes cybersecurity agencies (CISA, NSA, ASD, CCCS, NCSC) published “Careful Adoption of Agentic AI Services” in May 2026. Their key recommendations: enforce least-privilege access for AI agents, add human-in-the-loop checkpoints for irreversible actions, treat all external content as untrusted input, validate instructions at every agent boundary, and vet third-party tool integrations like software vendors.
What is prompt injection in agentic AI?
Prompt injection is an attack where malicious instructions are hidden inside data the AI agent reads — a document, a webpage, an API response, or a tool output. When the agent processes that data, it may treat the hidden instructions as legitimate commands. In agentic systems, this can cause the agent to take unauthorized actions on real systems. It’s one of the primary supply-chain and behavioral risks the Five Eyes guidance highlights.
How do multi-agent pipelines create security risks?
Multi-agent pipelines use one orchestrating agent to direct multiple specialized sub-agents. Each handoff between agents is a trust boundary — but most pipelines treat inter-agent messages as trusted by default. A compromised orchestrator, or a sub-agent that receives injected instructions through its inputs, can cause the entire pipeline to take unauthorized actions. The mitigation is validating inputs at every agent boundary, the same way you would validate external inputs at an API endpoint.
Is agentic AI covered by existing security frameworks like NIST or ISO 27001?
Existing frameworks provide the right principles — least-privilege, defense-in-depth, zero-trust — but were not written with autonomous AI agents in mind. The Five Eyes guidance explicitly recommends “folding agentic controls into existing cybersecurity frameworks” rather than treating AI security as a separate domain. Organizations already running NIST CSF or ISO 27001 programs should extend their existing asset inventory, access controls, and audit logging to cover AI agents and their tool integrations.
For more on how frontier AI models are handling their own security posture, see Claude Fable 5’s approach to cybersecurity guardrails and our breakdown of the best AI coding assistants for development teams weighing the tradeoffs between capability and control.
Last Updated: June 2026





