








Imagine standing at the edge of a vast mountain range, feeling the exhilaration and awe that comes with witnessing something truly extraordinary.
That’s the feeling I had when I first encountered Falcon 180B, the largest openly available language model that has taken the world by storm.
But it’s not just its size that sets Falcon 180B LLM apart.
This remarkable model has been trained on a diverse range of data, from web content to technical papers and code, allowing it to excel in a wide array of natural language tasks.
Its state-of-the-art performance surpasses other open-access models and even rivals proprietary ones, making it a true game-changer in the field of language model development.
The potential that Falcon 180B holds for various language-related endeavors is immense, and its integration and accessibility make it a tool that can be harnessed by anyone with a thirst for linguistic exploration.
So, buckle up and get ready to unleash the power of Falcon 180B as we embark on a thrilling journey to new linguistic heights!
Key Takeaways
- Falcon 180B is the largest openly available language model with 180 billion parameters.
- Unprecedented Training Effort: Trained on 3.5 trillion tokens across 4096 GPUs, powered by Amazon SageMaker, totaling ~7,000,000 GPU hours.
- Falcon 180B achieves state-of-the-art results across natural language tasks.
- Falcon 180B is one of the most capable LLMs publicly known.
- Falcon 180B can be commercially used but under restrictive conditions.
What is Falcon 180B?
You won’t believe the groundbreaking power of Falcon 180b llm, the open-source LLM that surpasses all previous models with its massive 180 billion parameters and unmatched benchmark performance.
A Giant Leap in Architecture
In the realm of architecture, Falcon 180B llm represents a monumental stride forward from its predecessor, the Falcon 40B. It seamlessly incorporates and advances upon the groundbreaking concept of multiquery attention, resulting in a remarkable boost in scalability. To gain a deeper understanding of this architectural marvel, it is highly recommended to peruse the inaugural blog post that unveiled the Falcon series developed by the Technology Innovation Institute.
The Herculean Training Process
Falcon 180B underwent a rigorous training regimen, setting new standards in computational prowess. This mammoth model was trained on a staggering 3.5 trillion tokens, harnessing the collective power of up to 4096 GPUs in perfect synchronization. The process, conducted on Amazon SageMaker, amounted to an astonishing ~7,000,000 GPU hours. To put this into perspective, Falcon 180B outstrips Llama 2 by a factor of 2.5, owing to its training with four times the computational capacity.
The Rich Tapestry of Data
The foundation of Falcon 180B is built upon a diverse dataset, primarily sourced from RefinedWeb, constituting a substantial 85%. Complementing this, the model also draws from a curated blend of data, including conversations, technical papers, and a fractional infusion of code, amounting to around 3%. This pretraining dataset boasts such colossal proportions that even the colossal 3.5 trillion tokens utilized represent less than a single epoch.
Fine-Tuning for Excellence
The chat model derived from Falcon 180B undergoes a meticulous fine-tuning process. It is nurtured on a diverse array of chat and instructional datasets, culled from expansive conversational resources.
Navigating Commercial Use
For those considering commercial applications, it’s imperative to be cognizant of the stringent conditions governing Falcon 180B’s utilization. Notably, commercial use is permissible with certain limitations, with the exception of “hosting use.” Prior to embarking on any commercial venture, it is strongly advised to scrutinize the license and seek guidance from your legal counsel.
In conclusion, Falcon 180B emerges as a behemoth in the world of AI models, redefining standards of scale, architecture, and computational prowess. As the latest addition to the Falcon family, it carries forward a legacy of innovation and excellence, poised to revolutionize the landscape of artificial intelligence.
Benchmark Performance
Is Falcon 180B Truly the Pinnacle of LLM Technology?
Falcon 180B stands as a beacon of excellence in the realm of openly released Large Language Models (LLMs). In a head-to-head comparison, it outshines both Llama 2 70B and OpenAI’s GPT-3.5 on MMLU metrics. Remarkably, it shares the podium with Google’s PaLM 2-Large on a multitude of evaluation benchmarks including HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, and ReCoRD. Depending on the specific evaluation criteria, Falcon 180B typically positions itself between the formidable GPT 3.5 and the anticipated GPT4. The prospect of further fine-tuning by the community promises to be an intriguing development now that it’s available for public use.
Palm 2 Comparison
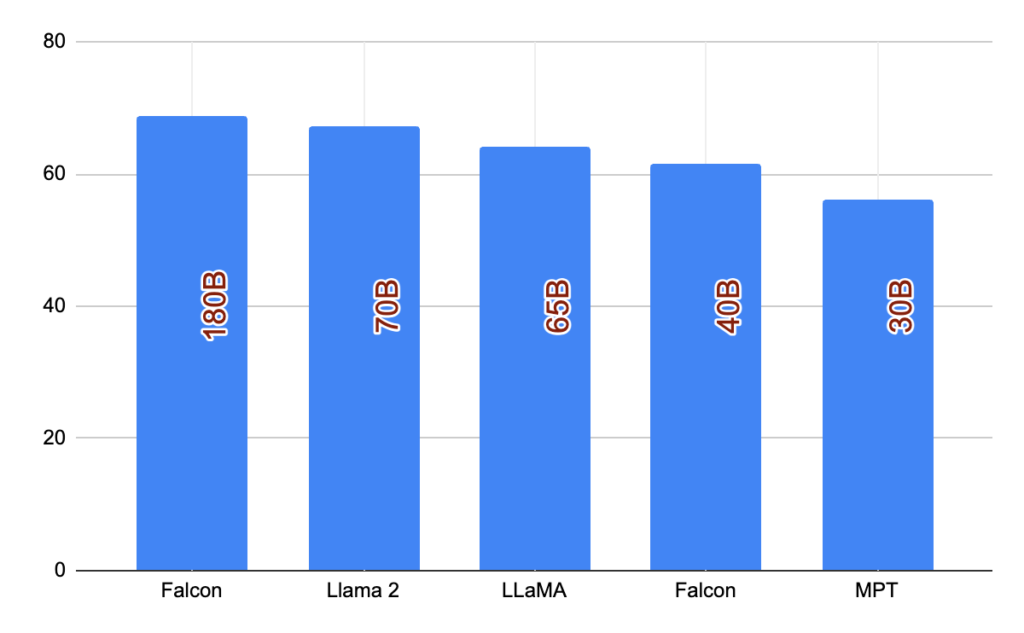
Falcon 180B Soars to the Top
With an impressive score of 68.74 on the Hugging Face Leaderboard, Falcon 180B claims the throne as the highest-scoring openly released pre-trained LLM. This accomplishment eclipses Meta’s LLaMA 2, which boasts a commendable score of 67.35.
Model Specifications and Performance Metrics
| Model | Size | Leaderboard Score | Commercial Use/License | Pretraining Length |
|---|---|---|---|---|
| Falcon | 180B | 68.74 | 🟠 | 3,500B |
| Llama 2 | 70B | 67.35 | 🟠 | 2,000B |
| LLaMA | 65B | 64.23 | 🔴 | 1,400B |
| Falcon | 40B | 61.48 | 🟢 | 1,000B |
| MPT | 30B | 56.15 | 🟢 | 1,000B |

Hardware Requirements as Per Hugging Face
Unveiling the Essential Specifications
According to Hugging Face’s comprehensive research and data, we present the critical hardware specifications necessary for optimal utilization of the Falcon 180B model across diverse use cases. It is important to emphasize that the figures presented here do not represent the absolute minimum, but rather the minimal configurations based on the resources available within the scope of Hugging Face’s research.
| Type | Kind | Memory | Example |
|---|---|---|---|
| Falcon 180B | Training | Full Fine-tuning | 5120GB – 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB – 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB – 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB – 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB – 8x A100 40GB |
These specifications, sourced from Hugging Face’s extensive research, serve as the cornerstone for unlocking the full potential of the Falcon 180B model, ensuring impeccable performance across a wide array of scenarios.
You can test yourself Falcon 180B llm demo here You have the ability to evaluate yourself by trying out the Falcon 180B llm demo.
According to a Runpod article
To run Falcon-180B, a minimum of 400GB of VRAM (Video Random Access Memory) is required. This means you’ll need hardware with substantial graphics processing capabilities. Specifically, at least 5 A100 GPUs are recommended. However, in practical use, it might be more effective to have 6 or more A100 GPUs, as 5 may not be sufficient for certain workloads. Alternatively, using H100 GPUs could also be a suitable option. Keep in mind that using hardware with less VRAM than recommended may result in reduced performance or may prevent the model from running properly.
Credits and Acknowledgments
The successful release of this model, complete with support and evaluations within the ecosystem, owes its existence to the invaluable contributions of numerous community members. Special recognition goes to Clémentine and Eleuther Evaluation Harness for LLM evaluations, Loubna and BigCode for their work on code evaluations, and Nicolas for providing essential inference support. Additionally, credit is due to Lysandre, Matt, Daniel, Amy, Joao, and Arthur for their efforts in seamlessly integrating Falcon into transformers.
Frequently Asked Questions (FAQs)
Q1: What is Falcon 180B?
Answer: Falcon 180B is a cutting-edge model released by TII, representing a scaled-up version of the Falcon 40B. It incorporates innovative features like multiquery attention for enhanced scalability.
Q2: How was Falcon 180B trained?
Answer: Falcon 180B llm underwent training on an impressive 3.5 trillion tokens, utilizing up to 4096 GPUs concurrently. This extensive training process spanned approximately 7,000,000 GPU hours, making Falcon 180B 2.5 times larger than Llama 2 and trained with four times more compute.
Q3: What is the composition of Falcon 180B’s training dataset?
Answer: The dataset for Falcon 180B primarily comprises web data from RefinedWeb, accounting for around 85%. Additionally, it incorporates a mix of curated data, including conversations, technical papers, and a small fraction of code (approximately 3%).
Q4: Can Falcon 180B llm be used for commercial purposes?
Answer: Yes, Falcon 180B can be employed for commercial use, although there are specific and restrictive conditions in place, particularly excluding “hosting use”. It is advisable to review the license and consult your legal team if you intend to use it for commercial applications.
Q5: How does Falcon 180B compare to other models like Llama 2 and GPT-3.5?
Answer: Falcon 180B surpasses both Llama 2 70B and OpenAI’s GPT-3.5 on MMLU metrics. Depending on the evaluation benchmark, it typically positions itself between GPT 3.5 and GPT4. Further fine-tuning by the community is expected to yield interesting developments now that it’s openly released.
Q6: What are the hardware requirements for running Falcon 180B?
Answer: According to Hugging Face’s research, the hardware requirements for Falcon 180B vary depending on the use case. For instance, full fine-tuning during training necessitates 5120GB of memory with an example configuration of 8x A100 80GB.





