


DeepSeek just made every AI model it runs 60–85% faster — without training a new model. The trick is called DSpark, it is fully open-source, and it may be the most important inference engineering advance of 2026.
What Is DeepSeek DSpark?
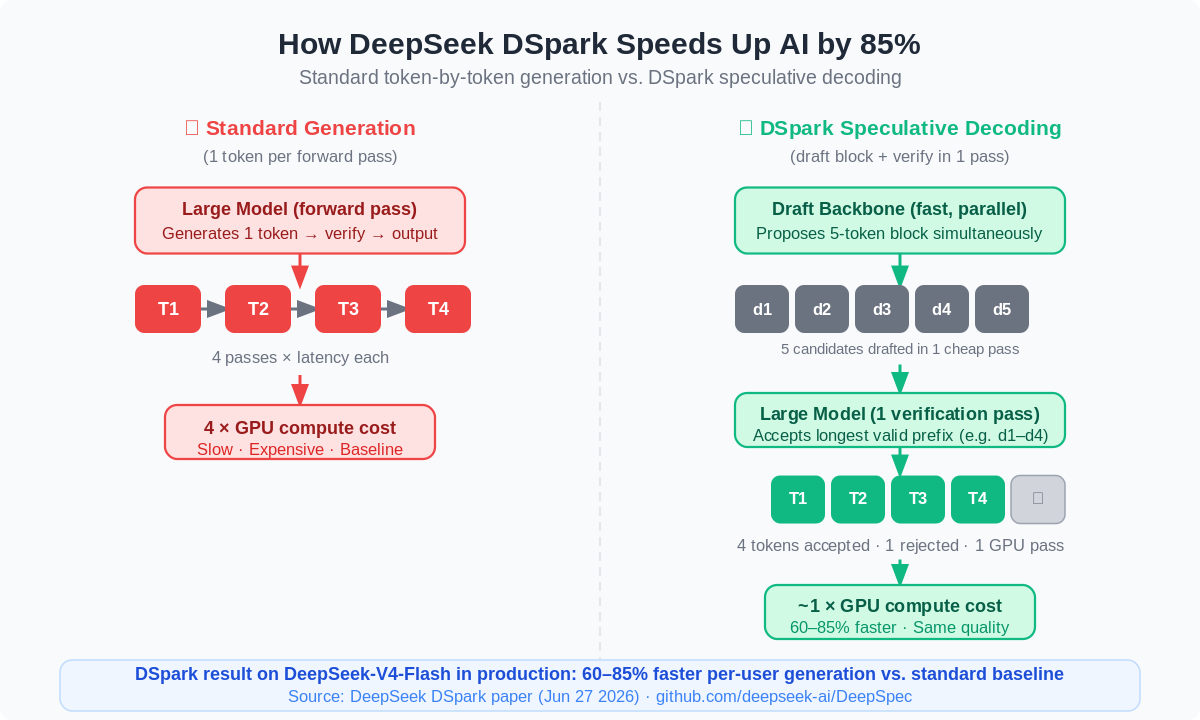
DSpark is a speculative decoding framework released by DeepSeek and Peking University on June 27, 2026. It accelerates the rate at which large language models generate text by having a cheap “draft” model propose multiple tokens at once, then using the large model to verify the entire block in a single pass. Valid tokens are accepted; any rejected token triggers a fallback. The net result on DeepSeek’s own production infrastructure: 60–85% faster per-user output on DeepSeek-V4-Flash, 57–78% faster on V4-Pro, with zero degradation in output quality.
This is not a new model. DSpark reuses the existing DeepSeek-V4 weights unchanged — it is purely a serving-layer optimization. DeepSeek also simultaneously open-sourced DeepSpec, an MIT-licensed training and evaluation codebase that lets any developer apply DSpark-style speedups to their own deployments, along with ready-to-use checkpoints on Hugging Face.
How Speculative Decoding Works — The Core Idea
Standard LLM inference is inherently sequential: generate one token, feed it back in, generate the next, repeat. Each step is a full forward pass through a multi-billion-parameter model. That is slow, and it is expensive — every user query ties up GPU time for every single token until the response is done.
Speculative decoding breaks that bottleneck. A small, fast “drafter” model proposes a block of candidate tokens in parallel — think of it as a rough draft. The large model then runs a single verification pass over the entire block, accepting any prefix of tokens that match what it would have generated on its own, and rejecting the first mismatch. If the drafter is good enough that it usually gets the first four out of five tokens right, you get four tokens for roughly the cost of one large-model pass. The speedup is real: more tokens accepted per pass equals lower latency, lower cost, higher throughput.
The difficulty has always been building a drafter that is fast and accurate enough to produce meaningful acceptance rates across diverse prompts. Previous approaches like Eagle3 (autoregressive, accurate but slow drafting) and DFlash (parallel but with “suffix decay” — acceptance rates falling off for later tokens in a block) each solved part of the problem. DSpark combines both approaches and adds a key innovation: a Markov head.
What Makes DSpark Different: The Markov Head
DSpark introduces a semi-autoregressive architecture. The parallel backbone drafts all tokens in the block simultaneously — capturing the speed of DFlash. Then a lightweight sequential head (rank-256 factorization, less than 1% of full model compute) conditions each candidate token on the previous one — capturing the positional accuracy of Eagle3. This module is called the Markov head because it operates like a Markov chain: each position only needs to know the prior position, not the entire sequence.
The practical effect: “suffix decay” is eliminated. Where DFlash saw acceptance rates drop steeply at positions 3, 4, and 5 in a draft block, DSpark maintains high acceptance all the way through. The offline benchmark tells the story clearly — DSpark exceeds Eagle3 by 26.9–31.0% on Qwen3 models and exceeds DFlash by 16.3–18.4%, according to the DSpark paper.
DeepSeek also ships a load-aware scheduler: when GPUs are underloaded, the verifier processes longer draft blocks; when GPUs are busy, it processes shorter ones. This keeps efficiency gains proportional to real-world traffic conditions rather than only showing up on benchmark hardware.
What This Means for AI Costs and the Industry
Inference cost is the central economics problem of the current AI market. Every major AI provider — OpenAI, Anthropic, Google, Mistral — spends a substantial fraction of revenue on GPU compute to serve responses. An 80% speedup per user request means either 80% lower cost for the same throughput, or 80% more users served on the same hardware. Either outcome is structurally significant for the economics of AI APIs.
This has implications beyond DeepSeek. DSpark was tested not only on DeepSeek-V4 but also on Qwen3 and Gemma4 variants — meaning DeepSpec, the open-source codebase, can in principle apply the same framework to any model. The MIT license removes any legal friction for adoption. DeepSeek has now established a pattern: release foundational efficiency advances as open source, forcing competitors to match the new performance floor or explain why they haven’t. This follows the same playbook as the original DeepSeek-V3 release that shocked Silicon Valley in January 2025.
The practical near-term impact: DeepSeek API users will see lower latency on V4-Flash and V4-Pro — no action required on their end. Developers building on DeepSeek R1 on Azure or other third-party hosts will need to wait for those platforms to adopt DSpark. And teams building private LLM deployments can immediately try DeepSpec to accelerate their own serving stack.
DSpark vs. Competing Approaches: Benchmark Summary
| Framework | Drafting Style | Suffix Accuracy | Production Speed Gain | Open-Source |
|---|---|---|---|---|
| Eagle3 | Autoregressive | High | ~40–50% | Yes |
| DFlash | Parallel | Low (suffix decay) | ~50–60% | Partial |
| DSpark (DeepSeek) | Semi-autoregressive | High (Markov head) | 60–85% | Yes (MIT) |
Source: DeepSeek DSpark paper, June 27 2026. Production figures from DeepSeek-V4-Flash under real-world load. Eagle3/DFlash figures are offline benchmark estimates from the same paper.
How to Get DSpark
DSpark is available now. The DeepSeek-V4-Pro-DSpark and DeepSeek-V4-Flash-DSpark checkpoints are on Hugging Face at huggingface.co/deepseek-ai. The full DeepSpec codebase — including training scripts, evaluation harnesses, and the DSpark architecture — is on GitHub at github.com/deepseek-ai/DeepSpec under MIT license. The DSpark paper PDF is included in the same repository.
For teams already using DeepSeek’s API, no action is needed — the speedup is deployed server-side. For open-source deployments on competing infrastructure, DeepSpec provides the tooling to port DSpark-style speculative decoding to your own model of choice, including Qwen3 and Gemma4 variants that were validated in the paper.
Frequently Asked Questions
What is DeepSeek DSpark?
DSpark is an open-source speculative decoding framework from DeepSeek and Peking University that makes large language models generate text 60–85% faster. It works by having a cheap draft model propose a block of candidate tokens in parallel, which the large model then verifies in a single forward pass — accepting the longest valid prefix. It was released on June 27, 2026, alongside the DeepSpec codebase on GitHub.
Does DSpark change the quality of DeepSeek’s outputs?
No. DSpark is a serving-layer optimization that leaves model weights completely unchanged. The verification step ensures that only tokens the large model would have generated on its own are accepted. Any token the draft model got wrong is rejected and the large model corrects the sequence — so output quality is mathematically identical to standard generation.
How fast is DSpark compared to standard LLM generation?
In production on DeepSeek-V4-Flash, DSpark delivers 60–85% faster per-user output generation compared to the standard single-token baseline. On DeepSeek-V4-Pro, the gain is 57–78%. In offline benchmarks against competing speculative decoding frameworks, DSpark exceeds Eagle3 by 26.9–31.0% and DFlash by 16.3–18.4% on accepted-token-length metrics.
Can DSpark be used with non-DeepSeek models?
Yes. The DeepSpec codebase, released simultaneously under an MIT license, includes training scripts and evaluation harnesses designed to work with any LLM. DeepSeek validated DSpark-style gains on Qwen3 and Gemma4 model families in the paper, and the open-source tools enable developers to train their own draft models for other architectures.
What is the Markov head in DSpark and why does it matter?
The Markov head is DSpark’s key innovation — a lightweight sequential module (rank-256 factorization) that conditions each position in the draft block on the previous token. This eliminates “suffix decay,” the problem where purely parallel draft models become inaccurate at positions 3, 4, and 5 in a block. By making each position aware of the prior one at almost zero compute cost, DSpark combines the speed of parallel drafting with the accuracy of autoregressive drafting.